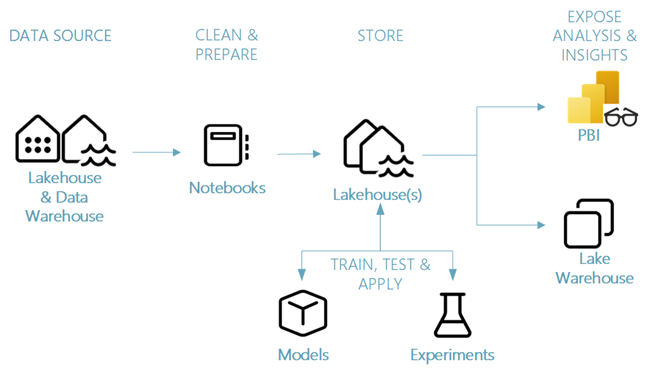
Powering the Full Data Science Journey in One Platform.
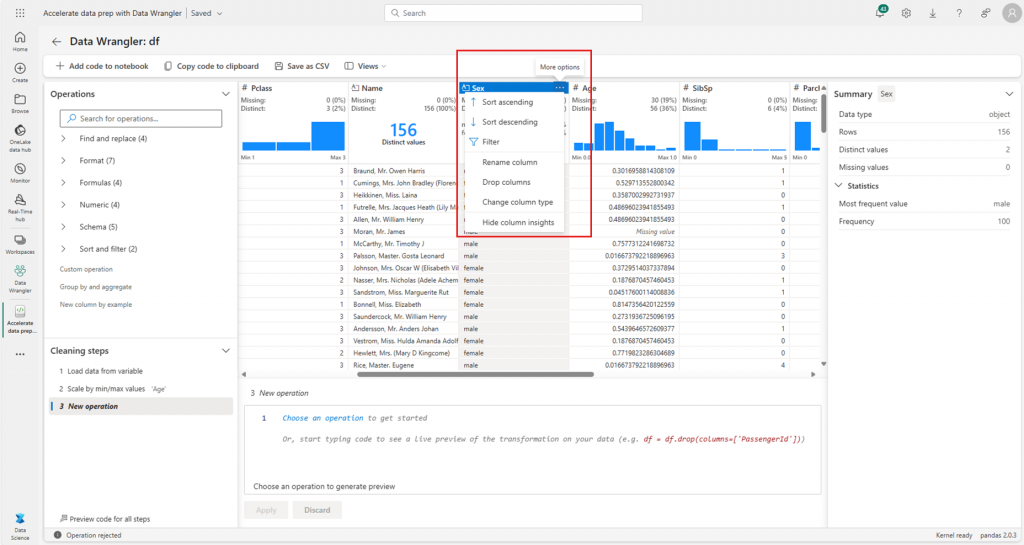
Data wrangler for interactive data preparation
Data Wrangler provides an intuitive interface for data scientists to explore, clean, and transform datasets. It offers dynamic data displays, built-in statistics, and visualization tools, enabling users to perform data wrangling tasks with minimal coding. Additionally, Data Wrangler generates corresponding Python code for each operation, promoting reproducibility and collaboration.
Seamless integration with notebooks
Integrated platforms often offer tools for creating visual representations of data, such as histograms, scatter plots, and box plots. These visualizations help in identifying patterns, trends, and anomalies within the data, facilitating a deeper understanding and aiding in the formulation of hypotheses for further analysis.
Built-in data profiling & quality assessment tools
This feature includes tools that automate the detection and correction of data quality issues, such as handling missing values, correcting inconsistencies, and standardizing formats. Automation streamlines the data preparation process, reducing manual effort and minimizing errors, thereby accelerating the overall data analysis workflow.
Integrated MLflow for experiment management
Fabric incorporates MLflow, an open-source platform for managing the machine learning lifecycle. This integration enables data scientists to log parameters, code versions, metrics, and output files during model training, ensuring comprehensive tracking and reproducibility of experiments.
Collaborative notebooks with real-time editing
Fabric provides collaborative notebooks that support real-time co-authoring, allowing multiple users to work simultaneously on data exploration, analysis, and modeling tasks. This feature enhances team productivity and fosters a collaborative environment for data science projects.
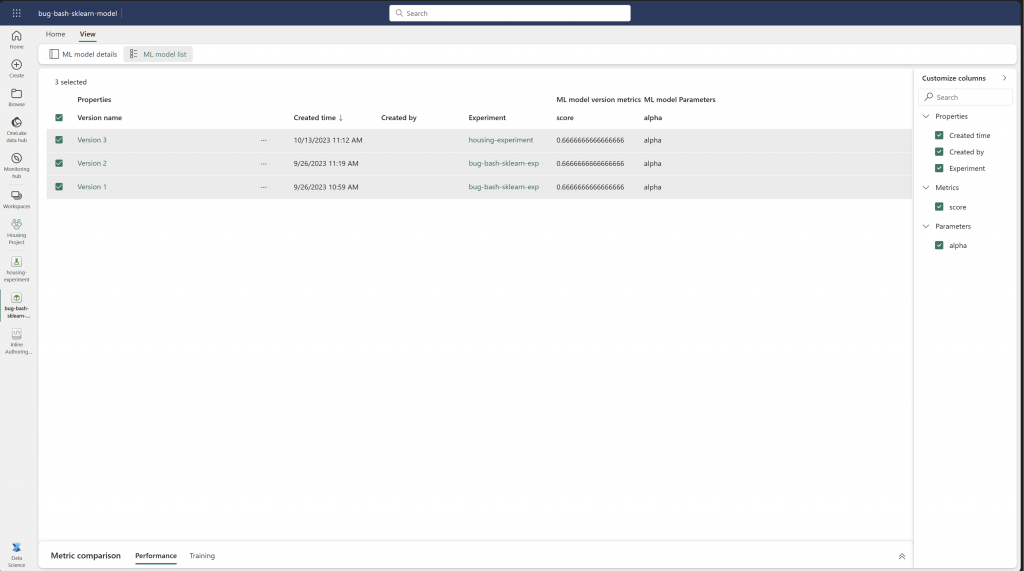
Centralized model registry & version control
Fabric offers a centralized model registry that facilitates the storage, versioning, and management of machine learning models. This centralized approach ensures that team members can access the latest model versions, track changes, and maintain consistency across deployments.
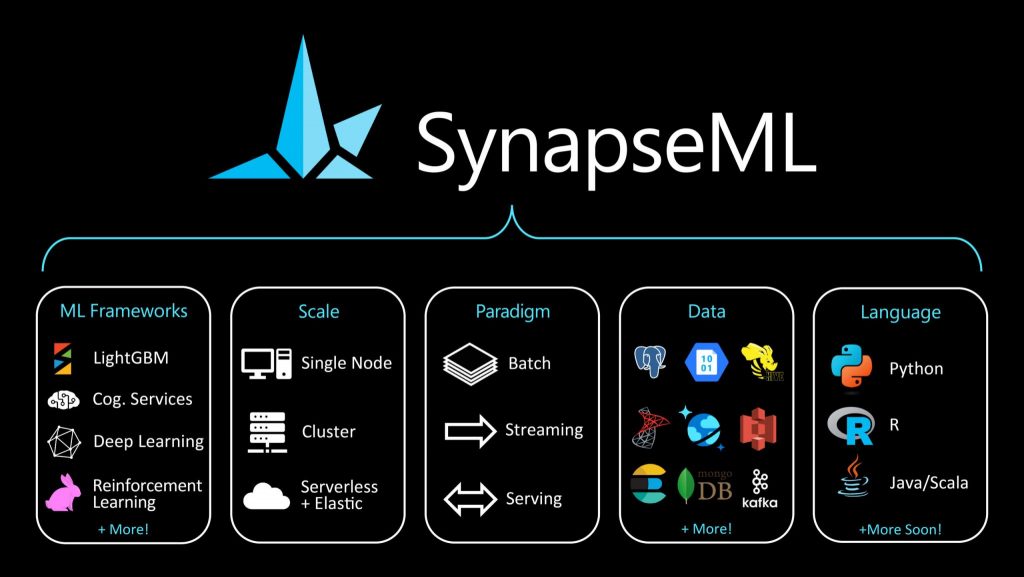
Integration with SynapseML for scalable machine learning
Fabric incorporates SynapseML, an open-source library that simplifies the creation of scalable machine learning pipelines. Built on Apache Spark, SynapseML enables distributed training and evaluation of models across large datasets, facilitating tasks such as anomaly detection, computer vision, and text analytics.
Predict function for batch scoring
Fabric provides the PREDICT function, which allows users to operationalize machine learning models by performing batch scoring across various compute engines. This function supports models saved in the MLflow format and enables the generation of batch predictions directly from notebooks or model item pages, streamlining the deployment process.
Seamless integration with Power BI for real-time insights
Fabric’s integration with Power BI enables the visualization of prediction results in real-time. By leveraging Direct Lake mode, users can access the latest predictions without the need for data loading or refresh, facilitating timely and informed decision-making.